
Un modelo dimensional, también conocido como diseñó dimensional, puede ser un gran aliado a la hora de ayudarnos a medir procesos de negocios con evidencia (datos), por lo que en este artículo explicaré desde que necesidad empresarial surgen, a que tipo procesamiento de datos se asocian y cuales son sus principales características y ventajas.
Usualmente las empresas buscan que sus procesos se vuelvan cada vez más óptimos, por lo que continuamente evalúan tecnologías para lograrlo. Como resultado suelen comprar más software y/o incorporar más módulos de un gran software (Ej: ERP SAP). Como he mencionado en artículos previos, esto genera de forma natural, una arquitectura conocida como Spider Web: Telaraña creciente en el tiempo, con diversos sistemas interactuando para soportar la operación pero dificultando cada vez más la integración.
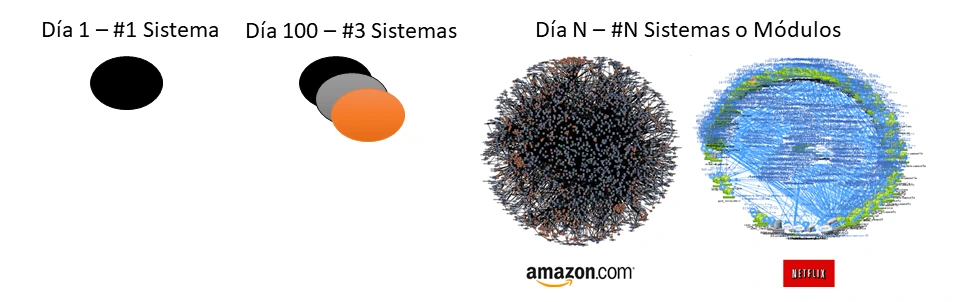
El problema surge cuando los desarrolladores y usuarios requieren usar estos datos, ya que para lograrlo deben conocer bastante de los sistemas (y sus modelos), los cuales muchas veces son sistemas cerrados o poco amigables. Algo no menos importante a resaltar es que dichos softwares se construyeron con fines operacionales por lo tanto difícilmente se les pueda exigir fines analíticos.
Conceptualmente un Data Warehouse surge para enfrentar las falencias que se producen en la arquitectura Spider Web procurando facilitar el acceso 360º a los datos. Sin embargo, tan pronto nos adentremos en el proyecto nos tocará preguntarnos “cómo diseñarlo”.
A la fecha existen 3 estrategias fundamentales para modelar un Data Warehouse:
La mayoría de estrategia disponibles en internet se basan en las previamente mencionadas incluso hay empresas perspicaces las cuales se asociaron con los autores para brindar a sus tecnologías el concepto de arquitectura.

Es importante destacar que los principios de estas estrategias son distintos, cuentan con diferencias conceptuales significativas. Por ejemplo, el concepto de Datamart en Corporate Information Factory es diferente al propuesto por el grupo Kimball. En este artículo hablaremos del Modelo Dimensional propuesto por Kimball.
Antes de profundizar en el Modelamiento Dimensional, es necesario revisar las diferencias entre OLTP y OLAP, ya que es la base de las estrategias mencionadas.
El procesamiento OLTP (Procesamiento de Transacciones en Línea) se centra en la gestión eficiente de las transacciones diarias. Se caracteriza por operar bajo múltiples operaciones concurrentes de lectura y escritura de datos en tiempo real. En OLTP principalmente se busca asegurar la consistencia, atomicidad y durabilidad de los datos.
Por otro lado, OLAP (Procesamiento Analítico en Línea) se enfoca en analizar o medir procesos de negocios, usualmente mediante grandes conjuntos de datos que proporcionan información estratégica para la toma de decisiones. Bajo este enfoque se suelen realizar consultas complejas y análisis de tendencias a lo largo del tiempo.
La siguiente tabla presenta un resumen para ambos tipos de procesamiento.
| Diferenciación | Sistemas Transaccionales (Operacionales) | Sistemas Analíticos |
| Propósito | Ejecución/registro de procesos de negocio | Medición de los procesos de Negocio. |
| Tipo de Interacción | Insertar, actualiza, borrar y consultar | Consultas |
| Alcance de las Interacciones | Transacciones Individuales | Transacciones Agregadas |
| Tipo de Consultas | Predecibles y estables | Impredecibles y cambiantes |
| Foco | Datos Actuales | Datos Actuales e Históricos |
| Estrategia de Optimización | Alta concurrencia | Alto rendimiento en consultas |
| Principios de Diseño | Tercera Forma Normal *(ER- 3FN) | Modelo Dimensional, Hub Spoke, Data Vault |
| Otros nombres Relacionados | OLTP, Sistemas Origen | Data Warehouse, Data Mart |
Consideremos el caso de una clínica o un hospital. El procesamiento OLTP equivaldría a registrar las operaciones diarias, tales como citas médicas, atención ambulatoria, exámenes, días cama, etc. Cada vez que un paciente asiste (o no), se crean registros asociados al episodio y/o se actualiza el inventario (según el tipo de atención). Es decir, se registran los detalles asociados a la atención (transacción) en tiempo real, asegurando que los datos estén actualizados y precisos (idealmente).
En OLAP, el enfoque es el análisis que realiza el área administrativa o el equipo médico a partir de los datos registrados, tales como evaluar identificar los prestaciones/médicos más populares, analizar los “no show”, etc., para así planificar estrategias futuras.
Por lo tanto, OLTP y OLAP tienen fines distintos, el modelo dimensional se inserta en el enfoque OLAP.
Un modelo dimensional nos facilita presentar los datos de procesos claves de las empresas con la finalidad de obtener insights que se materializan en acciones. Por lo tanto, al ser un modelo, es una posible forma de representar la realidad, no existe una solución única.
¿Qué características debiese tener un modelo para fines analíticos? Según Kimball el modelo dimensional debe:
Si bien el origen de modelo dimensional se remonta a un proyecto de investigación realizado por General Mills y la universidad de Dartmouth en la década del 60, fue el grupo Kimball quien popularizó el término y desarrolló una serie de técnicas.
Nota: El grupo Kimball siempre ha hecho énfasis de que los modelos dimensionales no se presentan en 3 forma normal a los usuarios porque violan la características previamente mencionadas.
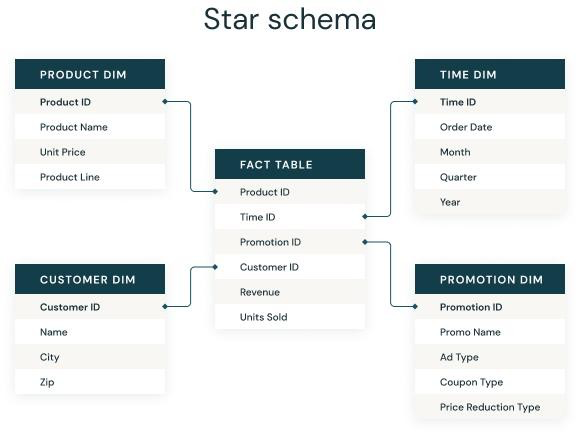
Nota: Existen varios tipos de fact table y dimensiones, en próximos artículos veremos técnicas para diseñarlas.
Los modelos dimensionales son bastante populares por varias razones, entre ellas:
Una “pillería o abuso de lenguaje” de grandes empresas e incluso consultores expertos es que hablan de “modelado” pero en instancias de herramientas de visualización.
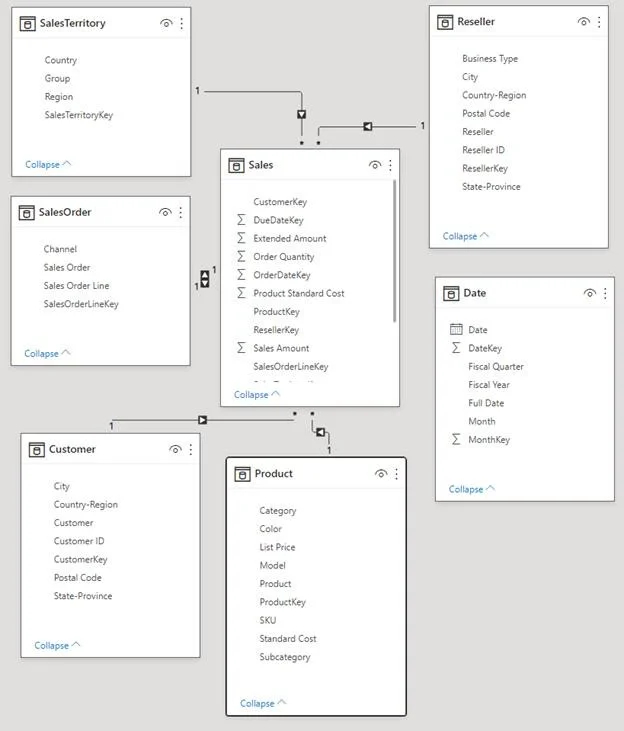
Para ser justos, el grupo Kimball y otros colegas como Christopher Adamson, durante años desarrollaron y presentaron las bases para que luego las herramientas saquen partido de esto. Por ejemplo, no es casualidad que en Power BI Desktop no se pueda unir 2 tablas por más de un campo y/o con más tablas (fuerza el Predictable Join). No es casualidad de que en Sap Business Object exista el concepto de loops en los universos. Que no se mal entienda, las herramientas de visualización son muy útiles, pero hay una serie de cosas que vienen antes, entre ellas el modelo de datos dimensional.
Si llegamos al consenso que un Data Warehouse esta para apoyar la toma decisiones, vale la pena pensar en estrategias que permitan publicar los datos de estos de la forma más efectiva posible. En particular los modelos dimensionales han demostrado excelentes resultados a la hora de habilitar a los usuarios para el autoconsumo (Self Services).
Un síntoma de que un modelo dimensional está bien implementado, es cuando “las preguntas analíticas crean respuestas que generan más preguntas de analíticas” y el proceso de crear reportes/dashboard para responder a estas nuevas preguntas es sencillo, en parte gracias al modelo y las herramientas que explotan las ventajas de estos.
Por otro lado, considerando que al 2024 el número de sistemas sigue creciendo (sensores, rrss, etc), es probable que se sigan requiriendo integraciones, ergo Data Warehouses. Es difícil pensar que llegue un gran sistema que cumpla con OLAP y OLTP por lo que vale la pena seguir invirtiendo en conocimiento, perfiles y modelos para cada contexto.
Nota: Si crees que este contenido puede ser útil para otras personas no dudes en compartirlo. Además te invitamos a seguirnos en Linkedin, Twitter, Facebook, Instagram y Youtube. Mientras en el Blog liberamos contenido más extenso, en las RRSS publicamos semanalmente tips relacionados con Data Warehouse, BI, Data Science y Visualización de Datos que es justamente lo que más nos apasiona hacer en Lituus.


