A la fecha, la metodología Kimball cuenta con más de 30 años de vida y numerosos casos de éxitos. Sin embargo, resulta natural preguntarse si puede aplicarse a la situación actual y futura donde contamos con más datos, a mayor velocidad y variedad (big data) que hace 30 años atrás. La respuesta es sí, la metodología Kimball puede ser útil para tomar decisiones con datos, sean estos Gigas, Teras o Exabytes.
Ahora bien, si los datos no son de calidad, por muchos Terabytes disponibles será bien difícil que ocupemos la plataforma analítica que los suministra. Por lo tanto, no es solo el aspecto tecnológico (big data) que hay que cuidar.
Parafraseando a Steve Jobs el “stay data hungry and stay data foolish” requiere que las organizaciones gestionen activamente sus activos, entre ellos los datos. En este artículo veremos cómo gestionar proyectos analíticos y la plataforma asociada mediante la metodología kimball (técnicamente del grupo Kimball).
Existen propuestas muy interesantes, por ejemplo, podemos encontrar el método BI Pathway. Este método propone insertar las iniciativas analíticas dentro de un portafolio que impacte los procesos de negocio core. Un enfoque distinto es Data Vault 2.0 Standard el cual persigue altos estándares de integración, escalabilidad y auditabilidad (SEI/CMMI) ofreciendo una arquitectura, metodología y buenas prácticas para lograrlo.
En este artículo revisaremos un framework pionero, propuesto por el grupo Kimball a mediados de los 80, conocido como “The Data Warehouse Lifecycle Toolkit”. Su mantra focus on the business es apalancado por 3 ejes: Tecnología, Datos y Business Intelligence.
Considera que las iniciativas analíticas deben ser guiadas con el negocio para resolver necesidades del negocio. ¿Esto significa que TI está cada vez más lejos? Eso quisieran algunos vende self services, pero no, la idea es construir junto a TI una plataforma de soporte para Business Intelligence.
Esta plataforma incluye una arquitectura conocida como Data Warehouse (DW).
Según la experiencia del grupo Kimball el mantra “focus on the business” implica:
Como dato anecdótico, a nivel de argot analítico, muchas personas promovieron el término BI para resumir todas las capas de la solución en un solo término. Es decir, BI podría incluir desde los modelos y ETLs hasta el delivery en formato de reportes, dashboard y Data Mining. A pesar de esto, la filosofía del grupo Kimball siempre fue considerar dos siglas: DW/BI, al más estilo de Batman y Robin. Desde su punto de vista, BI sin una arquitectura (DW) que los respalde no sería efectivo y viceversa.
Lector: Ok Lenin, pero entonces ¿siempre necesitare un Data Warehouse? ¿qué pasa con los mensajes del tipo “realice BI directo a sus fuentes de datos”?
Lenin: En general la respuesta es sí, necesitas una arquitectura llámese Data Warehouse, Data Lake, Data Vault o Lakehouse. A falta de una arquitectura, nuestros usuarios terminan convirtiéndose en “Ninjas Cinturón Negro del BuscarV”, trasladando valioso tiempo de análisis a la preparación de datos.
Una arquitectura permite ahorrar tiempo a mediano plazo, aporta linaje, gobernanza y credibilidad en los datos. Sin embargo, debemos diseñarla disciplinadamente, tal como lo esperaríamos en la elaboración de un puente.
Hasta aquí hemos revisado la base de Kimball para elaborar nuestro puente analítico, ilustrando el qué y para qué, ahora veremos el cómo hacerlo. Ponte cómodo porque lo que sigue es un poco más extenso de lo habitual.
¿Listo? Let’s rock!
El ciclo de vida es un roadmap general que describe la secuencia de tareas necesarias para un correcto diseño, desarrollo e implementación. Esta secuencia se presenta en el siguiente diagrama:
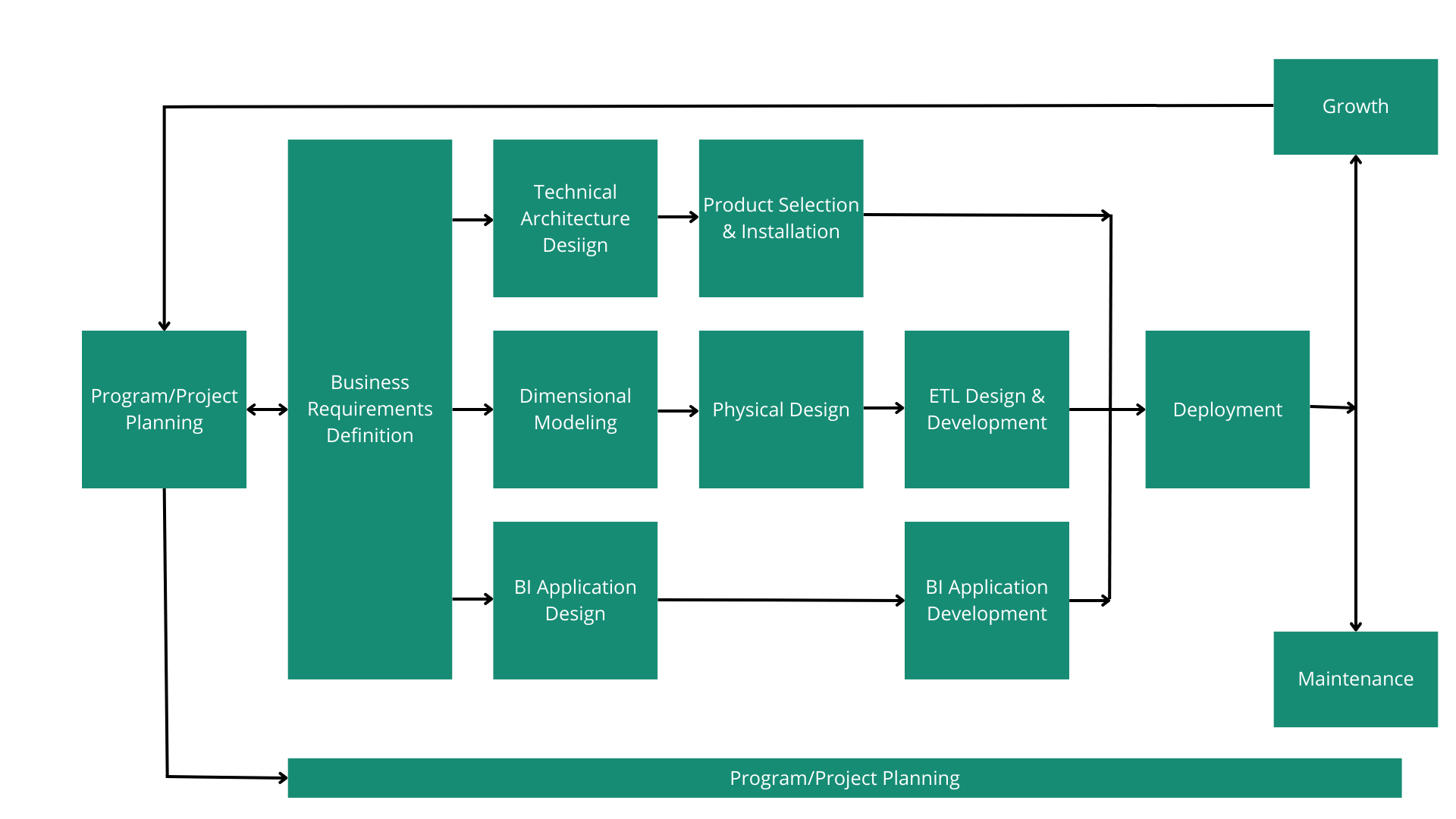
Usualmente las compañías cuentan con un plan estratégico que marca la pauta a seguir en los próximos años. La recomendación del framework es tomar como entrada dicho plan y proponer iniciativas analíticas (proyectos) que ayuden a medirlo con datos. Estas iniciativas (árboles) en conjunto conforman el programa analítico (bosque).
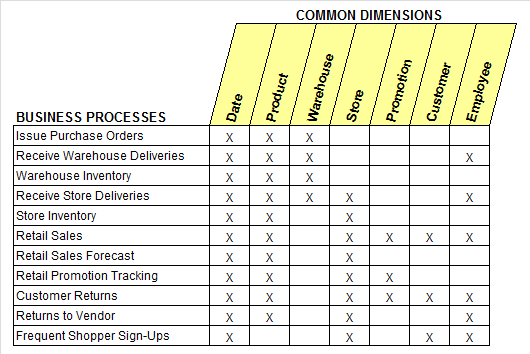
Una herramienta muy efectiva para comunicar el programa es la “Enterprise Data Warehouse Bus Matrix”. En esta matriz cada fila representa un proceso de negocio y cada columna es una dimensión con la cual se espera dar contexto a las métricas que se usarán para medirlo.
Es la tarea con el rectángulo más grande, recuerde el mantra que permea el framework – focus on the business -. Debemos entender cómo los usuarios operan en su día a día, averiguar qué datos utilizan y cuáles les faltan para cumplir sus objetivos. Si entendemos su situación actual (as is), es más probable que propongamos proyectos analíticos factibles (to be) que los impacte positivamente.
Probablemente detectaremos varias oportunidades, por lo que tendremos que priorizar. Una forma de hacerlo es usando una matriz que fue popularizada a principios de la década de 1970 por Boston Consulting Group.
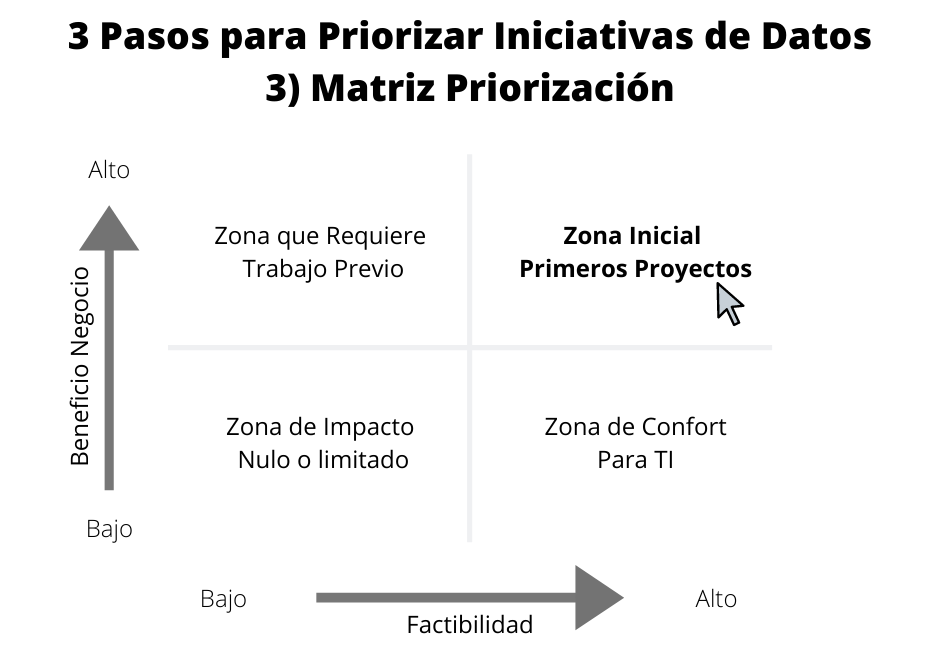
Le pediremos a los gerentes evaluar cada fila de la “Bus Matrix” respecto al beneficio que aporta al negocio. A su vez solicitaremos a TI que evalúe la factibilidad para entregar los datos asociados. Ubicaremos los resultados en la matriz de priorización y aquellos que se encuentren en el cuadrante superior derecho serán los primeros en ser implementados.
Otra estrategia válida es el método MoScoW. Sí, sé que mi nombre está ligado a un señor ruso y este método suena parecido a la capital de Rusia, pero en realidad es el acrónimo de Must have, Should have, Could have, Won’t have.
Las iniciativas analíticas (DW/BI) suelen enfrentarse a múltiples problemas, entre ellos: integración de datos e interoperabilidad de tecnologías. Antes de comprar algún producto, la recomendación es diseñar una arquitectura adecuada para la compañía.
El objetivo del diseño arquitectónico es establecer un framework y una visión de largo plazo considerando 3 factores claves. Los requerimientos del negocio, el entorno tecnológico actual (no es lo mismo extraer datos de SQL Server que AS 400, Cobol o de SAP) y el plan tecnológico de los próximos años. Como resultado obtendremos un listado de capacidades, componentes y requisitos de administración adaptados a nuestra organización.
Importante: Esta tarea nos invita a realmente pensar la plataforma que necesitamos y en lo posible evitar un pensamiento per alia del tipo: “si todos están hablando del software X y además está en lo más alto del cuadrante gartner, entonces deberíamos comprar el software x”.
Usando el diseño arquitectónico podremos informadamente “ir de compras” y/o desarrollar parte de los componentes que necesitemos. La decisión habitual es adquirir herramientas de ETL y visualización. Una vez que hemos concretado nuestro listado de productos, procedemos a instalar e instanciar nuestro ambiente analítico.

En esta etapa nos enfocaremos en crear modelos de datos lógicos que sean flexibles, fáciles de usar para los usuarios y cuyo rendimiento sea rápido a la hora de realizar consultas de grandes volúmenes de datos.
A diferencia de otros enfoques basados en la normalización como el de Inmon (CIF), se adopta la estrategia conocida como modelamiento dimensional. Si bien el grupo Kimball la popularizó, su origen se remonta a un proyecto de investigación realizado por General Mills y la universidad de Dartmouth en la década del 60.
A grandes rasgos esta estrategia clasifica los datos en hechos de medición (facts) o dimensiones que dan contexto a los hechos.
El paso de llevar nuestro modelo lógico a una base de datos se conoce como implementación física del modelo. Si nuestros modelos son creados en bases de datos relacionales, se les conoce como modelo estrella. En cambio, si son creados en bases de datos multidimensionales (por ejemplo Sap BW o MS Analysis Services) se les conoce como cubos OLAP.
Nota: Hay una serie de herramientas que nos permiten pasar de un modelo lógico a un modelo físico a casi un clic de distancia. Mi recomendación es que consideres usar alguna. Por ejemplo, podrías usar Oracle Data Modeler, Toad Data Modeler, Sap PowerDesigner o Erwin por nombrar algunas.
Los procesos de ETL consideran la extracción de datos de diversos sistemas, aplican criterios de calidad y consistencia de datos. Luego los unifican para que puedan ser utilizados en conjunto y finalmente entregan los datos, en un formato dimensional, para que los desarrolladores/analistas BI puedan crear aplicaciones y los usuarios finales puedan tomar decisiones.
Como mencione en Qué es ETL y 3 Pecados Capitales cometidos , esta tarea es compleja y requiere de mucho tiempo por lo que conviene desarrollarlos de una forma estructurada y repetible. Una muy buena pauta a seguir son los “34 subsistemas ETL”.
A pesar de que este artículo lo vas leyendo secuencialmente, es importante recalcar que los 3 ejes se pueden (y deberían) trabajar en paralelo.
En esta etapa identificamos y diseñamos aquellas aplicaciones que aportarán valor tempranamente. Además definiremos el medio o portal por el cual accederán nuestros usuarios y las capacidades que debería tener dicho portal (alertas, integraciones, envío de email, etc.).
Para nuestros usuarios, esta es la única capa visible del proyecto, pero cuidado, no basta con entregar reportes y dashboards efectivos. Es crucial que seamos ordenados en cómo los entregamos (home, carpetas, buscador, índices). Debemos preocuparnos de pulir la capa semántica, los metadatos y generar la documentación adecuada.
Nota: Una buena documentación facilita el onboarding a las herramientas seleccionadas en nuestra arquitectura (Power BI, Tableau , SAP SAC, etc.).
El deployment es la culminación de una iteración (proyecto analítico) que considera la unión de los 3 ejes claves. Sin embargo, tras el primer deployment, rápidamente surgen tareas de mantención (índices, particiones, respaldos, etc.). No subestimes las actividades de mantención ya que son claves para mantener una experiencia de los usuarios positiva.
Si nos fue bien, es casi seguro que la comunidad quiera más. Puede que algún área diga “cuándo nos tocará a nosotros” o exprese “queremos lo mismo”. Esto es una buena noticia ya que nuestra plataforma ha logrado una aceptación y por lo mismo seguirá creciendo.
Hay 3 aspectos que encuentro muy interesante de esta metodología:
Si crees que este contenido puede ser útil para otras personas no dudes en compartirlo. Además te invitamos a seguirnos en Linkedin, Twitter, Facebook, Instagram y Youtube. Mientras en el Blog liberamos contenido más extenso, en las RRSS publicamos semanalmente tips relacionados con Data Warehouse, BI, Data Science y Visualización de Datos que es justamente lo que más nos apasiona hacer en Lituus.
Referencias: